
What is Elasticsearch?
ElasticSearch is the Open Source Search Engine based on the Apache Lucene which uses JAVA to write and use Apache Lucene for indexing. Elasticsearch is basically providing the search functionality with the speed. Mainly Elasticsearch is useful to speed up the full-text search and make the full-text easier. In Elasticsearch, you can use the REST API to implement the search functionality without any complexity of Lucene.
Introduction:
Free
Open Source Under ALV2(Apache Lucene Version 2)
Distributed
Cross Platform
Restful(Native Java API)
Who is Using ElasticSearch?
Elasticsearch is capable of handling the massive amounts of data for full-text search, structured search and has been used by a large number of organizations which are listed below:
WordPress
Linkedin
Stack Overflow
GitHub etc
Use Cases:
The reason behind the success of Elasticsearch is, it’s constructing a way to allow the developer to implement any domain model mapped to the search technology with the explosive growth in the use cases.
Enterprise Search Including simple search, fuzzy search and aggregation.
Analytics and Reporting
GeoSpatial Search
Anomaly detection
Distributed JSON document database.
What Search Engine do?
Efficient indexing of data on all fields or combination of fields.
Analyzing Data
Tokenizing( finding word boundaries)
Streaming (reducing words to their root form)
Filtering (Removing stop words)
Relevance storing
From the matched document which one to show the first.
What is Apache Lucene?
Apache Lucene is the indexing and searching library which was created by the Apache Software Foundation.
What does Elasticsearch add to Lucene?
Restful Service( JSON API over HTTP)
High Availability and Performance.(Clustering)
What are the Major Benefits of Elasticsearch?
Easy to get going with it.
Shorter learning curve.
Fast, incisive search against the large volume of data.
Broadly distributed and highly scalable.
Actively developed with the good online document.
Terminology in Elasticsearch:
Let’s learn the Lucene vocabulary and architecture used for Elasticsearch. For Example, in RDBMS, you are calling database whereas the database is known as “Index” in Elasticsearch.
| RDBMS Term | Elasticsearch Term |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document – The main index and search the data. It contains one or more data fields. |
| Column | field – contains the names and values |
| schema | mapping |
| SQL | Query DSL |
How to download and Run Elasticsearch on windows?
Elasticsearch is mainly built in programming language JAVA and require at least JAVA 7 in order to run. Its only support Oracle’s Java and OpenDSL.
Installation of Elasticsearch is very simple. First of all, download the .zip folder from its official site and unpack that into a folder. Navigate to the bin directory in the folder, double click on elasticsearch.bat to run.you need to setup JAVA environment.
Elasticsearch uses 9200 interface port of HTTP REST API.After Started the server, You can ensure by using the following URL in the browser.
1 2 3 | http://localhost:9200 |
This command is used to get the basic information Elastics Search.This means you can use the Web browser to perform basic queries and requests but for more complex cases, you need to use command-line tools, such as cURL
You can easily install the Elasticsearch as a system service in Windows.Just go to the subfolder of the bin directory and execute:
1 2 3 | service.bat install | remove | start | stop | manager [SERVICE ID]// replace with desired service id |
How to store a Document?
SYNTAX:
1 2 3 | curl -X < verb > ' < PROTOCOL > : // < HOST > / < PATH > ? < QUERY_STRING > '-d' < BODY > ' |

Parameters:
Verb: Verb is the methods GET, POST, PUT, HEAD, or DELETE.
PROTOCOL: HTTP or HTTPS protocol
HOST: Host address of the machine installed Elastic
PORT: Elastic Services port number. Default is 9200
QUERY_STRING: Query String parameters are necessary to perform the operation.
BODY: A request you want action which is in json format
Here is the example to store a document in Elasticsearch.
1 2 3 4 5 6 7 8 | Curl -xPUT http://localhost:9200/prj/chef/1 -d { "firstname": "Bhumi", "lastname" : "Shah", "emai" : "test@thecreativedev.com" } |
Here is the data storage structure of Elasticsearch /{index}/{type}/{ID}. Originally data is saved as JSON.cURL command contain the new option -d parameter and this option are to load a text request that request body.
Document Storage:
A Simple Query in Elasticsearch:
Let’s understand the Elasticsearch query to get practical idea:
1 2 3 4 5 6 7 8 9 | Curl -xPOST { "query" :{}, "match" :{}, "Match_all": {} direct request all, "lastname":{} } |
You can import data through POST and HEAD is used to retrieve the data.The output is JSON structure.Here Parameters -X is a request method, the default value is GET.All the data that each document has a defined index and type in Elasticsearch
The Search API in action:
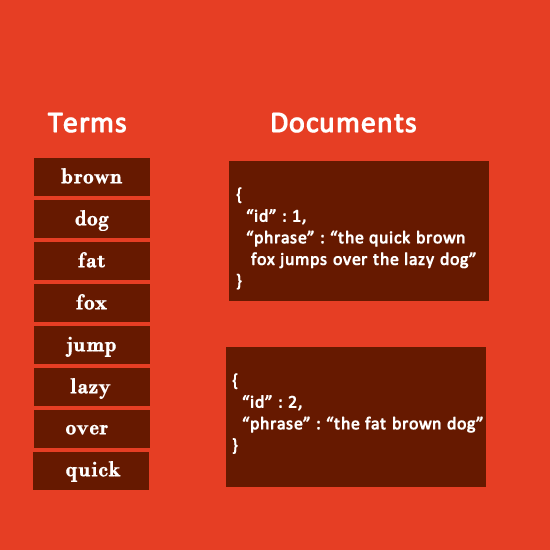
Inverted Index:
Inverted Index in Elasticsearch is for searching the each object component.
Aggregation:
Another useful feature in Elasticsearch is aggregation. Aggregation allow to calculate and summarize data query.is broadly categorized in two.
Bucket: Collection of doc that meet the criteria
Metrics: Statistics calculates on the doc in bucket
1 2 3 | SELECT COUNT(col1) FROM tablename GROUP BY col2; |
COUNT(col2) is equivalent to the Metrics, GROUP BY col2 is equivalent to the bucket.
Handling Relationship:
There are many relational data in the real world. Elasticsearch data format is flat, so you perform operation quickly without any lock.
1. Application side Joins
2. Data denormalization
3. Nested object
4. Percent/ Relationship
Application Side JOIN
It is the similar type to relational database Joins to achieve the data joining query.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | PUT /my_index/chef/1 { "name" : "Bhumi", "emaiil" : "test@thecreativedev.com", } PUT my_index/recipe/2 { "name" : "Test Recipe", "instruction" : "This is test instruction", "chef_id" : 1 } |
In this example, two indexes are created one for user and
Here You can see JSON document contains a set of fields and the each field have different forms.
Data DeNormalization:
Data DeNormalization will improve the query efficiency and work as expected to satisfy the query result.As data denormalization is good but is makes index large which is bad.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | PUT /my_index/chef/1 { "name" : "Bhumi", "emaiil" : "test@thecreativedev.com", } PUT my_index/recipe/2 { "name" : "Test Recipe", "instruction" : "This is test instruction", "chef" : { "id" : 1, "name" : "Bhumi" } } |
Nested Object:
Nested object is the way to join the nested documents to the root document. Nested object is very simple to understand, you can create nested level fields.
Let’s understand the Nested Object with the example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | PUT /my_index/recipe/1 { "name" : "Test Recipe", "instruction" : "This is test instruction",, "recipeType" : ['type1','type2'], "ingredients" : [ { "name" : "ingredient name", "amount" : "1 tbspoon", "date" : "20-Dec-2015 04:15", }, { "name" : "ingredient name2", "amount" : "2 tbspoon", "date" : "23-Dec-2015 04:15", } ] } |
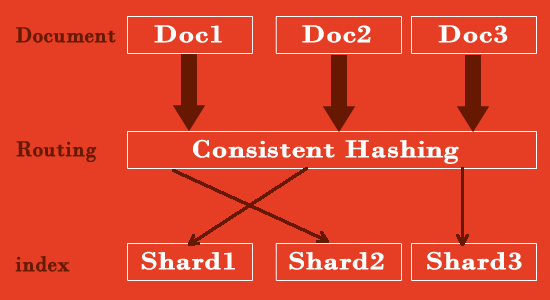
Distributed and Highly Available
1. In Elasticsearch following operation occur automatically
2. Partitioning document across an arrangement of distinct shards
3. In a multi-node cluster, distributing the document to shards to provide data redundancy and failover.
4. Routing requests from any node in the cluster to specific nodes containing the specific data needed.
Performance Tweaking:
1. Bulk Indexing
2. Multi get
Some Important Plugins for Elasticsearch:
1. Watchers: Define a query, condition, schedule and the actions to take and watched will alerted and notify you.
2. Shield: Shield allows to easily protect data with username and password. Advanced Security features like encryption, roles based access control and IP filtering.
Cons of Elasticsearch:
Here are the some points which are bad in Elasticsearch to keep in mind:
1. Extremely high write environment
2. Large amount of document
3. Transaction operation
4. Primary store
Conclusion
The Elasticsearch is easiest and fastest engine.I hope this article will help you to understand Elasticsearch.Keep in mind, however, that the most important aspect of Elasticsearch is the search without suffering a query performance.
Share your experience about Elasticsearch in the comment section. Have you ever used Elasticsearch or planning to use Elasticsearch in your application? if you have any query, let me know.















{kind=link}
Comments (2)